siglip_400m
The SigLIP model is a shape‑optimized model pre‑trained on the WebLI dataset, with a resolution of 384 × 384. It was introduced in the paper "Sigmoid Loss for Language‑Image Pre‑Training" by Zhai et al. and first released in Google Research's big_vision repository. SigLIP is a multimodal CLIP‑type model with an improved loss function that allows larger batch sizes without relying on global pairwise similarity normalization, and performs better with smaller batches. It is primarily used for zero‑shot image classification and image‑text retrieval. Training data include the WebLI dataset; images are resized to 384 × 384 and normalized, and text is tokenized and padded to 64 tokens. The model was trained for three days on 16 TPU‑v4 chips.
Description
SigLIP (shape‑optimized model)
Model Description
SigLIP is a multimodal model that builds on CLIP with an improved loss function. It operates on image‑text pairs without requiring a global view for normalization, enabling larger batch sizes while also performing well with smaller batches.
Intended Uses & Limitations
The model can be used for zero‑shot image classification and image‑text retrieval tasks.
How to Use
Example for zero‑shot image classification:
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
model = AutoModel.from_pretrained("google/siglip-so400m-patch14-384")
processor = AutoProcessor.from_pretrained("google/siglip-so400m-patch14-384")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["a photo of 2 cats", "a photo of 2 dogs"]
inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = torch.sigmoid(logits_per_image)
print(f"{probs[0][0]:.1%} that image 0 is {texts[0]}")
Or using the pipeline API for simplicity:
from transformers import pipeline
from PIL import Image
import requests
image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-so400m-patch14-384")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
outputs = [{"score": round(o["score"], 4), "label": o["label"]} for o in outputs]
print(outputs)
Training Process
Training Data
SigLIP was pre‑trained on the WebLI dataset.
Pre‑processing
Images are resized/scaled to 384 × 384 and normalized on the RGB channels with mean (0.5, 0.5, 0.5) and std (0.5, 0.5, 0.5). Text is tokenized and padded to a length of 64 tokens.
Compute Resources
The model was trained for three days on 16 TPU‑v4 chips.
Evaluation Results
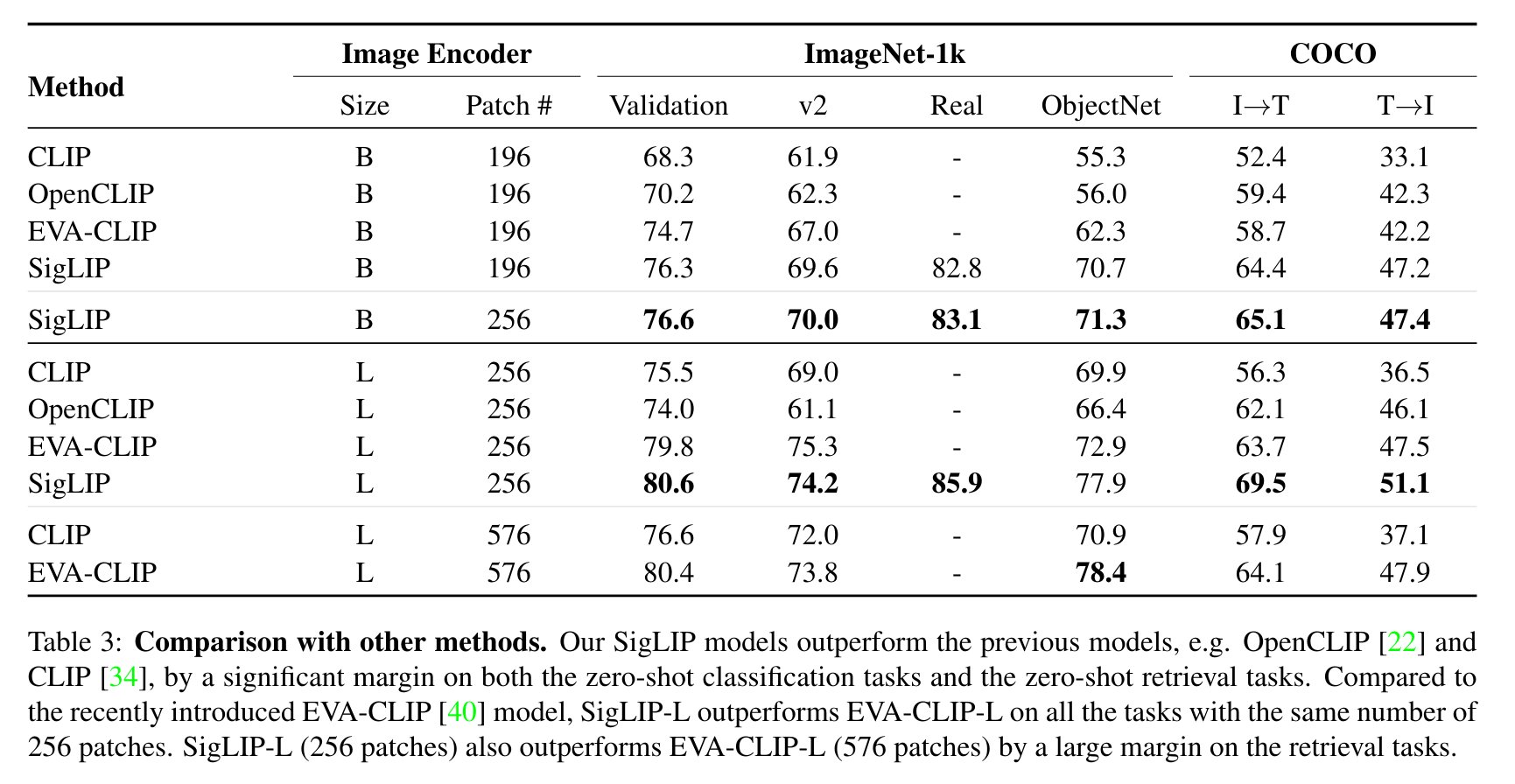
SigLIP’s evaluation results compared with CLIP are shown in the paper:
BibTeX and Citation
@misc{zhai2023sigmoid,
title={Sigmoid Loss for Language Image Pre‑Training},
author={Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer},
year={2023},
eprint={2303.15343},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
AI studio
Generate PPTs instantly with Nano Banana Pro.
Generate PPT NowAccess Dataset
Please login to view download links and access full dataset details.
Topics
Source
Organization: huggingface
Created: 12/2/2024
Power Your Data Analysis with Premium AI Models
Supporting GPT-5, Claude-4, DeepSeek v3, Gemini and more.
Enjoy a free trial and save 20%+ compared to official pricing.